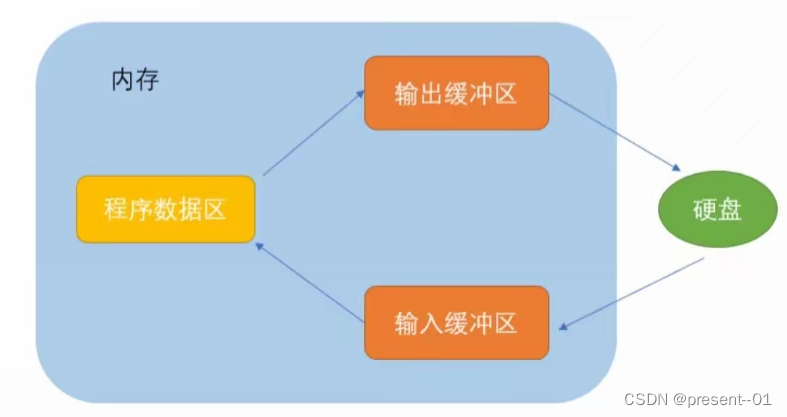
PyTorch是一个开源的机器学习框架,它提供了丰富的工具和库,用于构建和训练深度学习模型。PyTorch的基本定义如下:
张量(Tensor):PyTorch中的基本数据结构是张量,类似于多维数组。张量可以存储和操作数据,并支持GPU加速计算。
自动求导(Autograd):PyTorch使用自动求导技术来计算张量上的梯度。通过将操作封装在torch.Tensor对象中,PyTorch可以跟踪计算图并自动计算梯度。
模型定义:PyTorch允许用户通过定义模型的类来创建自定义的神经网络模型。用户可以定义模型的结构和参数,并实现前向传播函数。
模型训练:在PyTorch中,模型的训练通常包括以下步骤:
定义损失函数:选择适当的损失函数来衡量模型预测与真实标签之间的差异。
定义优化器:选择合适的优化算法来更新模型参数,以最小化损失函数。
迭代训练:通过多次迭代,将训练数据输入模型进行前向传播和反向传播,并根据优化器更新模型参数。
模型推理:在训练完成后,可以使用已训练的模型进行推理。通过将输入数据传递给模型的前向传播函数,可以获得模型的预测结果。